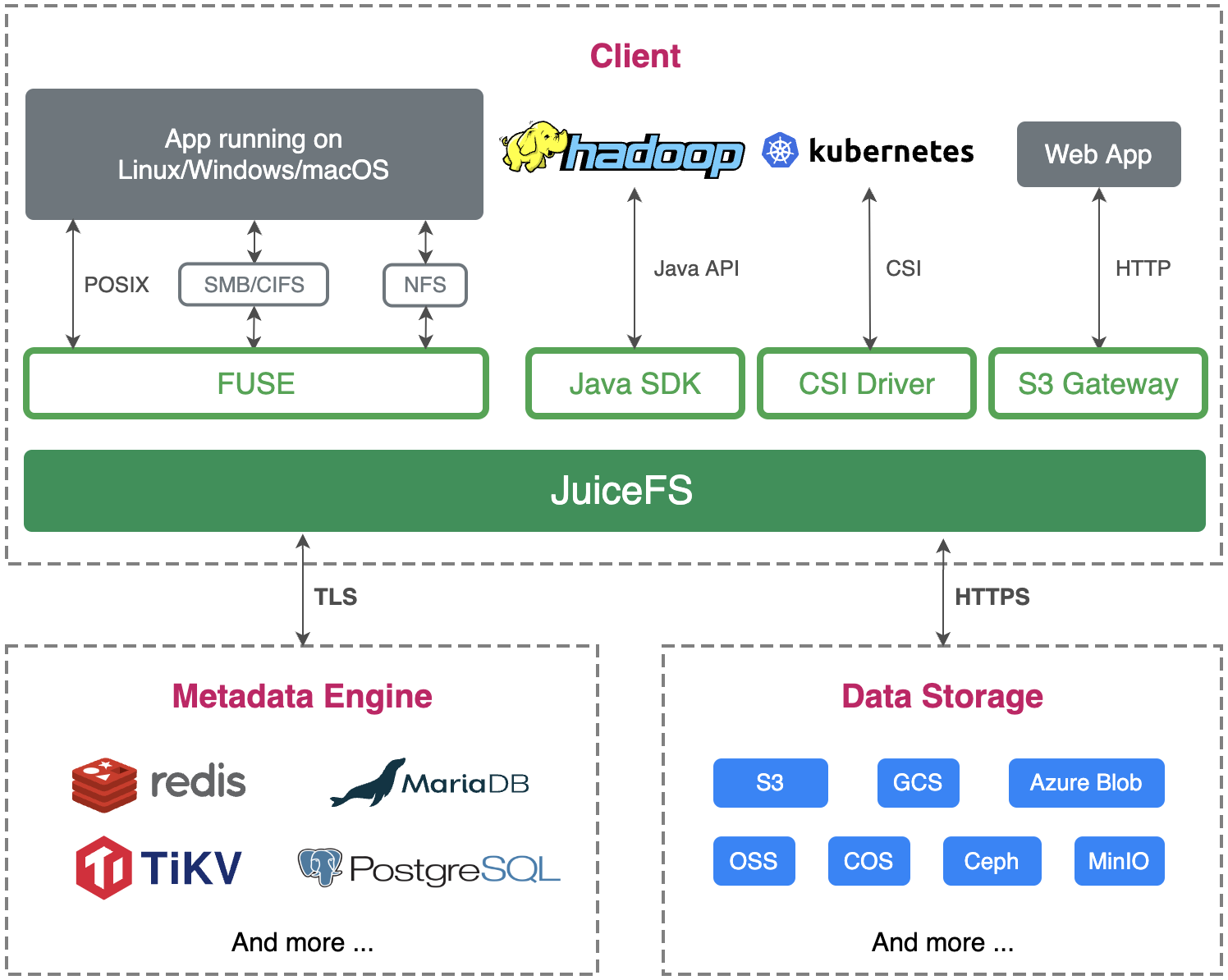
JuiceFS是一个在 Apache License 2.0 下发布的高性能POSIX文件系统,专为云原生环境而设计。通过 JuiceFS 存储的数据将持久化到对象存储(例如 Amazon S3)中,相应的元数据可以根据场景和需求持久化到 Redis、MySQL、TiKV 等各种兼容的数据库引擎中。
源代码
https://github.com/juicedata/juicefs
通过JuiceFS,海量云存储可以直接连接到生产环境中的大数据、机器学习、人工智能以及各种应用平台。无需修改代码,海量云存储就可以像本地存储一样高效使用。
JuiceFS(Juicedata File System)确实是一个高性能的POSIX文件系统,它充分利用了对象存储(如Amazon S3、阿里云OSS等)的经济性和近乎无限的容量,以及数据库(如Redis、MySQL、TiKV等)的元数据处理能力。这种设计使得JuiceFS能够很好地满足云原生环境中对海量数据存储和高效访问的需求。
在JuiceFS中,文件被分割成固定大小的块(chunks),这些块被存储在对象存储中。同时,文件的元数据(如文件名、文件大小、块的位置等)被存储在数据库中。这种架构使得JuiceFS能够同时提供高性能的文件访问和海量数据存储能力。
对于大数据、机器学习、人工智能等应用平台来说,JuiceFS提供了一个透明的存储层。这意味着这些应用平台可以直接访问存储在JuiceFS中的数据,而无需关心数据是如何存储和管理的。这对于简化数据管道、提高数据处理效率以及降低存储成本都非常有帮助。
此外,JuiceFS还支持多种访问协议(如NFS、SMB、FUSE等),这使得各种类型的应用(包括Linux、Windows、MacOS等操作系统上的应用)都能够方便地访问和使用存储在JuiceFS中的数据。这进一步增强了JuiceFS的通用性和灵活性。
总的来说,JuiceFS是一个专为云原生环境设计的高性能POSIX文件系统,它充分利用了对象存储和数据库的优势,为海量数据存储和高效访问提供了一个经济、可靠且易于集成的解决方案。
JuiceFS是一款分布式、轻量级的文件系统,专为云原生环境设计,支持多种应用场景。以下是一些JuiceFS的主要应用场景:
- 大数据分析:JuiceFS与Hadoop分布式文件系统(HDFS)兼容,并能与主流计算引擎(如Spark、Presto、Hive等)无缝衔接。这使得它成为处理大数据工作负载的理想选择,尤其是当数据量巨大且需要高性能、可扩展的存储解决方案时。
- 机器学习:由于JuiceFS支持POSIX标准,因此它可以与所有机器学习和深度学习框架兼容。这使得数据科学家和开发人员能够轻松地在JuiceFS上存储和访问训练数据集,从而提高团队协作和数据使用效率。
- 容器集群中的持久卷:JuiceFS提供了Kubernetes CSI支持,使得它可以在容器集群中作为持久卷使用。这意味着在容器化环境中运行的应用程序可以可靠地存储和访问数据,即使容器被重新调度或迁移。
- 共享工作区:JuiceFS可以在任意主机上挂载,没有客户端并发读写的限制。这使得它非常适合作为团队或项目之间的共享工作区,团队成员可以同时访问和修改文件,提高工作效率。
- 数据备份:JuiceFS提供了无限平滑扩展的存储空间,使得它可以作为数据备份的理想选择。结合共享挂载功能,可以将多个主机上的数据汇总到一处进行统一备份。
- 边缘计算:在火山引擎边缘计算等场景中,JuiceFS也得到了广泛的应用,为用户提供了高效、安全、可靠的存储服务。
总的来说,JuiceFS的灵活性和可扩展性使其能够适应多种不同的应用场景,从大数据分析到机器学习,从容器集群到共享工作区,再到数据备份和边缘计算等。