
前言
仅训练3小时,斯坦福团队发布了一款名为Alpaca的开源轻量级语言模型,这款模型在测试集中击败GPT-3.5(text-davinci-003),并且能够在消费级显卡上运行。这对于那些不拥有昂贵GPU的研究者、工程师和开发者来说,是个重大的好消息。Alpaca的推出让我们看到了,即使是在计算能力受限的条件下,也可以实现类似ChatGPT的自然语言处理任务。
Alpaca的训练数据集来源于text-davinci-003,这是OpenAI发布的一个大型自然语言处理模型。Alpaca在该数据集上进行了微调,并且在多项自然语言处理任务中表现出了优异的性能,甚至在一些任务中击败了text-davinci-003。这表明Alpaca具有很高的泛化能力和灵活性,可以适用于各种自然语言处理应用场景。Alpaca的表现进一步证明了其作为一款轻量级模型的出色性能,可为自然语言处理领域的研究者、工程师和开发者带来更多的技术选择。
为了让广大深度学习爱好和从业者更好的学习,我们翻译了原始文章并附带开源地址
翻译 Alpaca: A Strong Open-Source Instruction-Following Model

我们介绍了 Alpaca 7B 模型,这是在 52,000 个指令跟随演示的基础上从 LLaMA 7B 模型微调得到的。与 OpenAI 的 text-davinci-003 相比,Alpaca 的行为类似,但其体积非常小,而且易于/便宜复制(成本低于 600 美元)。
Overview
指令跟随模型(Instruction-following models)如 GPT-3.5(text-davinci-003)、ChatGPT、Claude 和 Bing Chat 变得越来越强大。许多用户现在定期与这些模型互动,甚至将它们用于工作。然而,尽管广泛部署,指令跟随模型仍然存在许多缺陷:它们可以生成虚假信息,传播社会刻板印象,并产生有害语言。
为了在解决这些紧迫问题上取得最大进展,学术界的参与非常重要。不幸的是,由于没有开源模型能够接近于诸如 OpenAI 的 text-davinci-003 之类的闭源模型的能力,因此在学术界研究指令跟随模型一直很困难。
我们发布了有关指令跟随语言模型的发现,该模型被称为 Alpaca,是从 Meta 的 LLaMA 7B 模型微调得到的。我们使用 text-davinci-003 的自我指导风格生成了 52,000 个指令跟随演示,并对 Alpaca 模型进行了训练。Alpaca 表现出许多与 OpenAI 的 text-davinci-003 相似的行为,但它也非常小而且易于/便宜复制。
我们发布了我们的训练方法和数据,并打算在未来发布模型权重。我们还提供一个交互式演示,以使研究社区更好地了解 Alpaca 的行为。交互可以暴露出意料之外的能力和失败,这将指导我们未来对这些模型进行评估。我们还鼓励用户在我们的网页演示中报告任何令人担忧的行为,以便我们更好地了解和缓解这些行为。由于任何发布都会带来风险,因此我们将在本博客文章后面讨论我们的思考过程。
我们强调,Alpaca 仅供学术研究使用,禁止任何商业用途。这个决定有三个因素:首先,Alpaca 基于 LLaMA,其具有非商业许可证,因此我们必然继承了这个决定。其次,指令数据基于 OpenAI 的 text-davinci-003,其使用条款禁止开发与 OpenAI 竞争的模型。最后,我们没有设计足够的安全措施,因此 Alpaca 还没有准备好用于一般用途的部署。
Training recipe
在学术预算下训练高质量的指令跟随模型存在两个重要挑战:一个是强大的预训练语言模型,另一个是高质量的指令跟随数据。最近,Meta发布了新的LLaMA模型,解决了第一个挑战。针对第二个挑战,self-instruct论文建议使用现有的强大语言模型自动生成指令数据。具体而言,Alpaca是一种语言模型,使用LLaMA 7B模型的监督学习进行微调,在OpenAI的text-davinci-003上生成了52K个指令跟随演示。
下面的图示说明了我们如何获得Alpaca模型。对于数据,我们通过构建自指方法(self-instruct method)来生成指令跟随演示。我们从自指种子集( self-instruct seed set)中的175个人工编写的指令-输出对开始。然后,我们提示text-davinci-003使用种子集作为上下文示例来生成更多指令。我们通过简化生成流水线(详见GitHub中的细节)并显著降低成本来改进了自指方法。我们的数据生成过程产生了52K个唯一的指令及其相应的输出,使用OpenAI API的成本不到500美元。
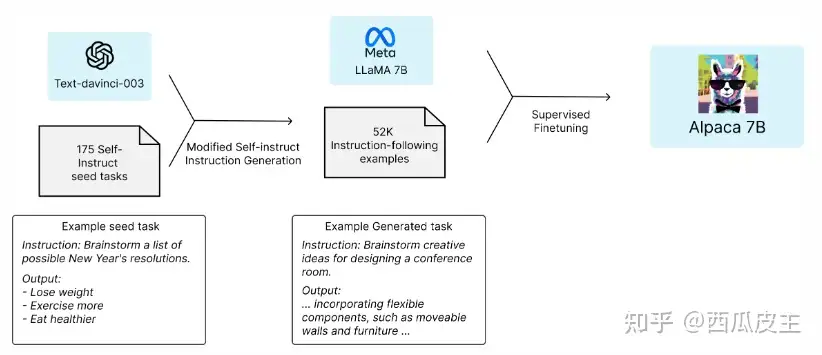
使用这个指令跟随数据集,我们使用Hugging Face的训练框架对LLaMA模型进行了微调,利用了全分片数据并行和混合精度训练等技术。在8个80GB A100上微调7B LLaMA模型耗时3小时,成本不到大多数云计算提供商的100美元。
Preliminary evaluation
为了评估Alpaca,我们对自我指导评估集中的输入进行了人工评估(由5位学生作者进行)。这个评估集是由自我指导作者收集的,涵盖了一系列面向用户的指令,包括电子邮件写作、社交媒体和生产力工具。我们在text-davinci-003和Alpaca 7B之间进行了盲成对比较,发现这两个模型的表现非常相似:在与text-davinci-003的比较中,Alpaca赢得了90v89的胜利。
考虑到模型的规模较小,指令跟随数据的数量也很适中,我们对这个结果感到非常惊讶。除了利用这个静态评估集,我们还在进行互动测试Alpaca模型,并发现Alpaca在各种输入上的行为通常与text-davinci-003相似。我们发布了Alpaca的互动演示,并鼓励读者自行评估Alpaca并给我们反馈。
在本节的其余部分,我们包括了几个交互示例,展示了Alpaca的能力和局限性。
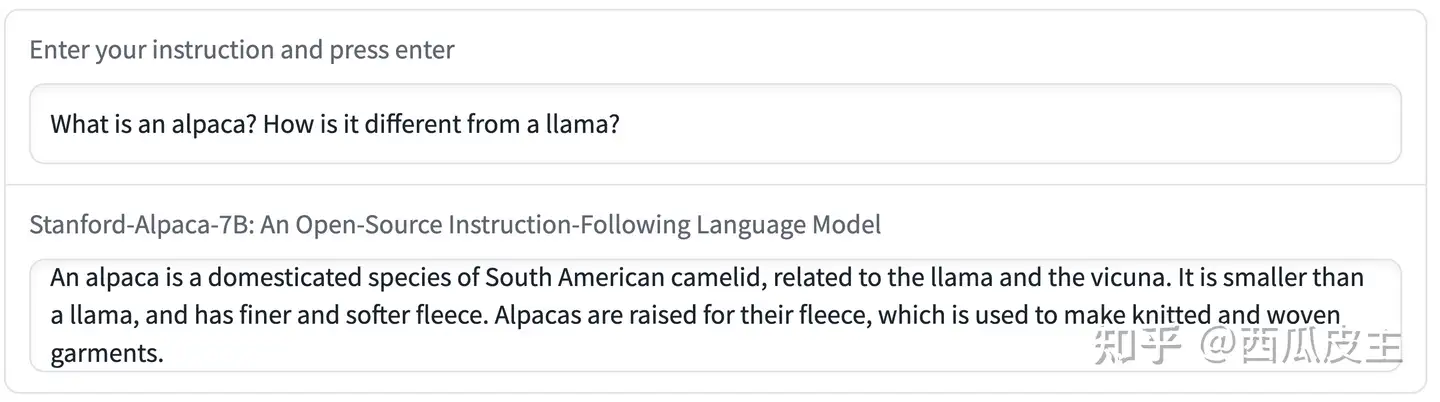
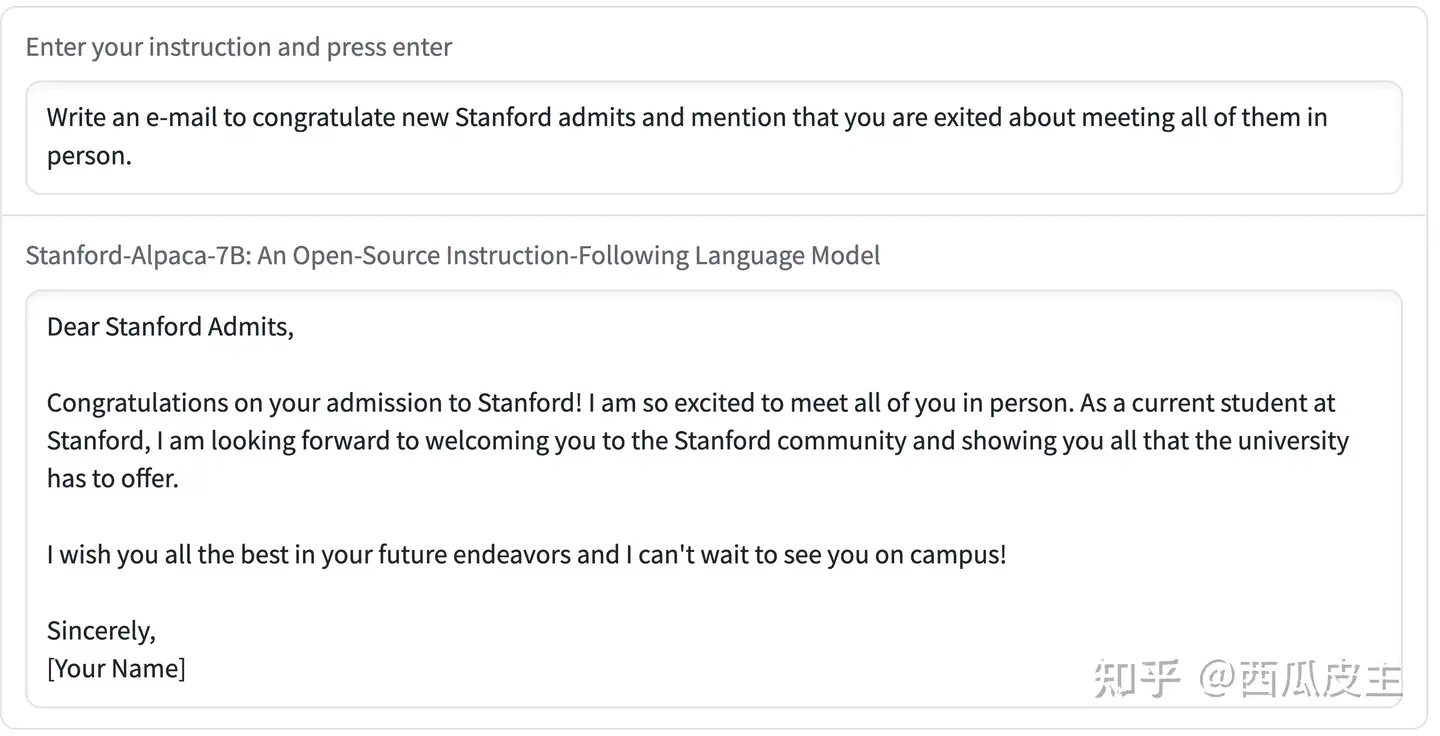
上面的例子表明,Alpaca的输出通常写得很好。我们注意到,Alpaca反映了指令跟随数据集的一般风格。因此,Alpaca的答案通常比ChatGPT短,反映了text-davinci-003较短的输出。
Known limitations(已知限制)
Alpaca还展示了语言模型的几个常见缺陷,包括幻觉(hallucination)、毒性(toxicity)和刻板印象(stereotypes)。特别是幻觉似乎是Alpaca的一种常见失败模式,甚至与text-davinci-003相比也是如此。
例如,在下图中,Alpaca错误地说坦桑尼亚的首都是达累斯萨拉姆,它是坦桑尼亚最大的城市。(在1974年之前,它一直是首都,后来被多多马取代)。

此外,Alpaca可用于生成传播错误信息的良好输出,如以下示例所示。
Alpaca很可能包含许多与底层语言模型和指令调整数据相关的其他限制。但是,我们认为该工件仍将对社区有用,因为它提供了一个相对轻量级的模型,可以作为研究重要缺陷的基础。我们鼓励用户通过在Web演示中标记它们来帮助我们识别新的故障类型。总体而言,我们希望发布Alpaca能促进对指令跟随模型及其与人类价值的一致性的进一步研究。
Assets released
今天我们将发布以下资产:
- 演示:一份互动演示,供所有人尝试使用 Alpaca。
- 数据:使用5.2万个演示进行了Alpaca的微调。
- 数据生成过程:生成数据的代码。
- 超参数:用于使用Hugging Face API微调模型的超参数。
我们计划在不久的将来发布以下资产:
- 模型权重:我们已经联系 Meta 获取指导,以发布 Alpaca 模型权重,包括 7B Alpaca 和经过微调的更大 LLaMA 模型的版本。
- 训练代码:我们的代码使用 Hugging Face 接口来访问 LLaMA。目前,支持 LLaMA 的工作仍在进行中,并不稳定。一旦 Hugging Face 正式支持 LLaMA,我们将提供确切的训练命令。
Release decision
我们相信发布上述资产将使学术界能够对指令遵循语言模型进行受控科学研究,从而产生更好的科学研究,最终提出新的技术来解决这些模型现有的缺陷。
同时,任何发布都存在一定的风险。首先,我们认识到发布我们的训练配方会揭示某些能力的可行性。一方面,这使更多人(包括恶意行为者)能够创建可能会造成伤害的模型(无论是有意还是无意的)。另一方面,这种意识可能会激励快速的防御性行动,特别是来自学术界的行动,现在可以利用这些手段对这种模型进行更深入的安全性研究。总体而言,我们认为对研究社区的好处超过了这次特定发布的风险。
鉴于我们正在发布训练配方,我们认为发布数据、模型权重和训练代码在配方的简单性下产生的风险非常小。同时,发布这些资产对于可重复的科学研究具有巨大的好处,这样学术界就可以使用标准的数据集、模型和代码进行受控比较和探索扩展。
同时,部署 Alpaca 的交互式演示也存在潜在的风险,例如更广泛地传播有害内容,降低垃圾邮件、欺诈或虚假信息的门槛。我们已经采取了两项风险缓解策略。首先,我们使用 OpenAI 的内容审查 API 实现了一个内容过滤器,该过滤器根据 OpenAI 的使用政策过滤出有害的内容。其次,我们使用 Kirchenbauer 等人在2023年描述的方法对所有模型输出进行了水印处理,以便他人可以(在一定的概率下)检测输出是否来自 Alpaca 7B。最后,我们对演示使用有严格的条款和条件;它仅限于非商业用途和遵守 LLaMA 的许可协议的用途。
我们明白这些缓解措施在我们发布模型权重或用户训练自己的指令遵循模型时可能被规避。然而,通过安装这些缓解措施,我们希望推进最佳实践,并最终制定社区规范,以负责任地部署基础模型。
Future directions
我们对Alpaca所开启的研究机会感到兴奋。未来有许多令人兴奋的方向:
- 评估:我们需要更加严谨地评估Alpaca。我们将从HELM(Holistic Evaluation of Language Models)开始,希望能够进化成为更多生成式的、遵循指令的情境。
- 安全性:我们希望进一步研究Alpaca的风险,并使用自动红队测试、审计和自适应测试等方法来提高其安全性。
- 理解:我们希望更好地理解训练配方如何产生这些功能。需要哪些基本模型属性?当你扩大规模时会发生什么?需要哪些指令数据的属性?使用self-instruct on text-davinci-003有哪些替代方法?
Acknowledgments(致谢)
Alpaca的实现直接且关键地依赖于现有工作。我们要感谢Meta AI Research训练并发布LLaMA模型,感谢self-instruct团队为我们提供数据生成管道的基础,感谢Hugging Face提供的训练代码,以及感谢OpenAI铺平了道路并展示了可以实现的目标。
我们还要强调,还有许多其他开源的指令跟随LLM和聊天模型的努力,包括OpenChatKit、Open Assistant和Carper AI。
https://github.com/tatsu-lab/stanford_alpaca


