

撰写关于人工智能现状的报告就像在不断变化的沙丘上建筑:当你发布时,整个行业已经发生了翻天覆地的变化。但是,斯坦福这本386页的报告仍然总结了这个复杂且快速发展领域的重要趋势和要点。
人类中心人工智能研究所的AI指数与学术界和私营行业的专家合作,收集有关这个问题的信息和预测。作为一个年度努力(从规模上看,你可以打赌他们已经在为下一份报告做准备了),这可能不是关于AI的最新观点,但这些定期的广泛调查对于了解行业动态是非常重要的。
今年的报告包括“关于基础模型的新分析,包括它们的地缘政治和训练成本,AI系统的环境影响,K-12 AI教育,以及AI领域的公共舆论趋势”,还有对一百个新国家的政策进行了研究。
让我们简要概括一下最高层次的要点:
- 在过去的十年里,人工智能的发展从以学术为主导转变为以产业为主导,差距很大,而且这种趋势没有任何改变的迹象。
- 在传统基准上测试模型变得越来越困难,这里可能需要一种新的范式。
- 人工智能培训和使用的能源足迹变得相当可观,但我们尚未看到它在其他方面可能增加的效率。
- 自2012年以来,“人工智能事件和争议”的数量增加了26倍,实际上这个数字似乎还有些偏低。
- 人工智能相关技能和职位发布在增加,但速度没有你想象的那么快。
- 然而,政策制定者们正在争相制定一部决定性的人工智能法案,这无疑是一项愚蠢的任务。 投资暂时停滞,但这是在过去十年里经历了天文数字的增长之后。
- 超过70%的中国、沙特和印度受访者认为人工智能的好处大于弊端。美国人呢?只有35%。
但这份报告详细讨论了许多主题和子主题,且非常易读且不涉及技术细节。只有真正专注的人才会阅读全部386页的分析,但实际上,任何有动力的人都可以阅读。
让我们更详细地看一下第3章,技术人工智能伦理。
偏见和毒性很难用指标来衡量,但只要我们能为这些问题定义和测试模型,就很明显可以看出,“未经过滤”的模型更容易导致问题。指令调整,也就是说在模型上添加额外的准备层(如隐藏提示)或将模型的输出通过第二个中介模型,可以有效改善这个问题,但离完美还有很远。
在前文提到的子弹中提到的“人工智能事件和争议”的增加,最好通过以下图表来说明:
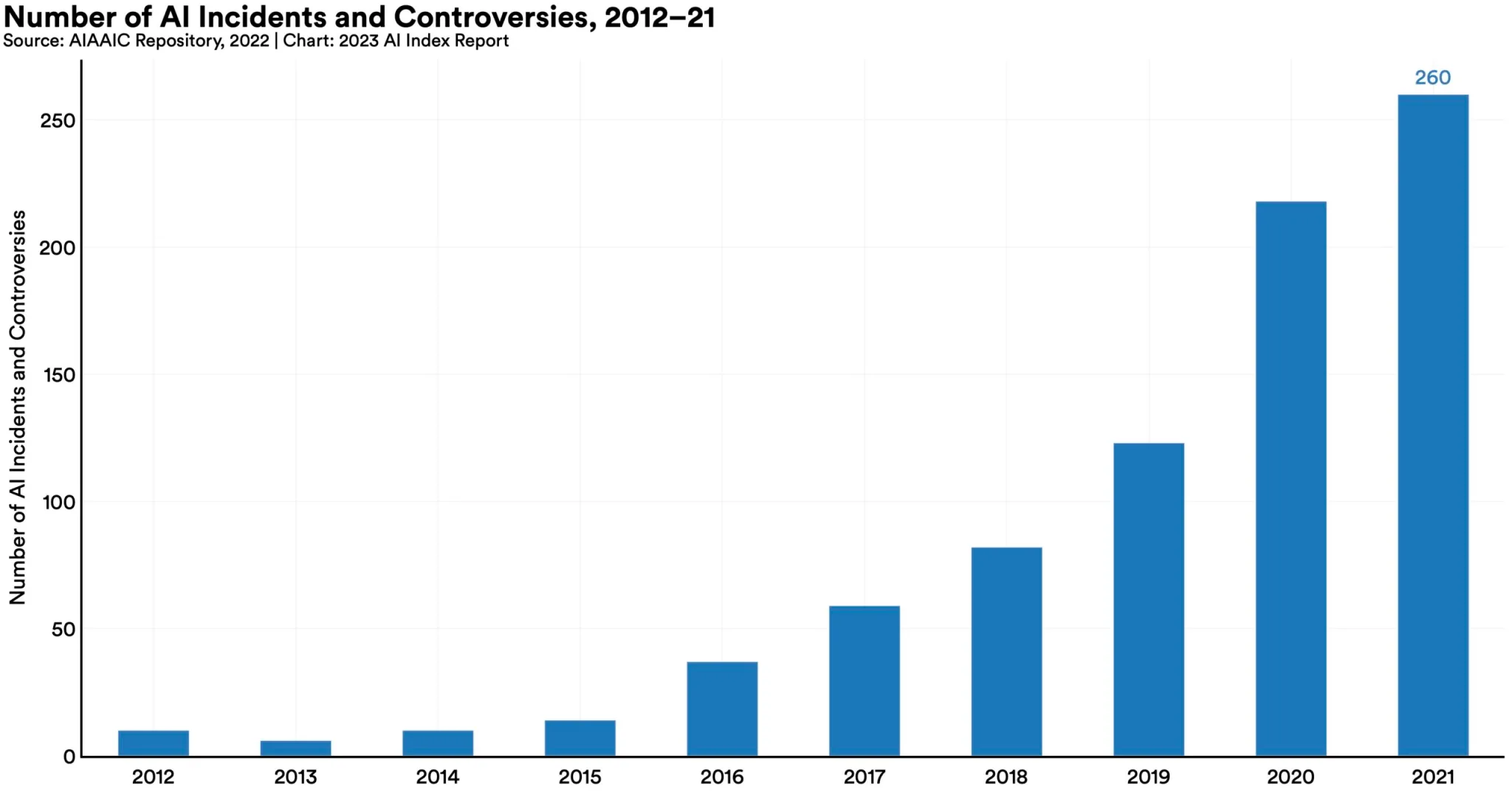
如您所见,这一趋势呈上升态势,这些数据还是在ChatGPT和其他大型语言模型被主流采用之前统计的,更不用提图像生成器的巨大进步了。您可以肯定,26倍的增长只是一个开始。
如下图所示,从某种方式上使模型更加公平或无偏见可能会在其他指标上产生意想不到的后果:
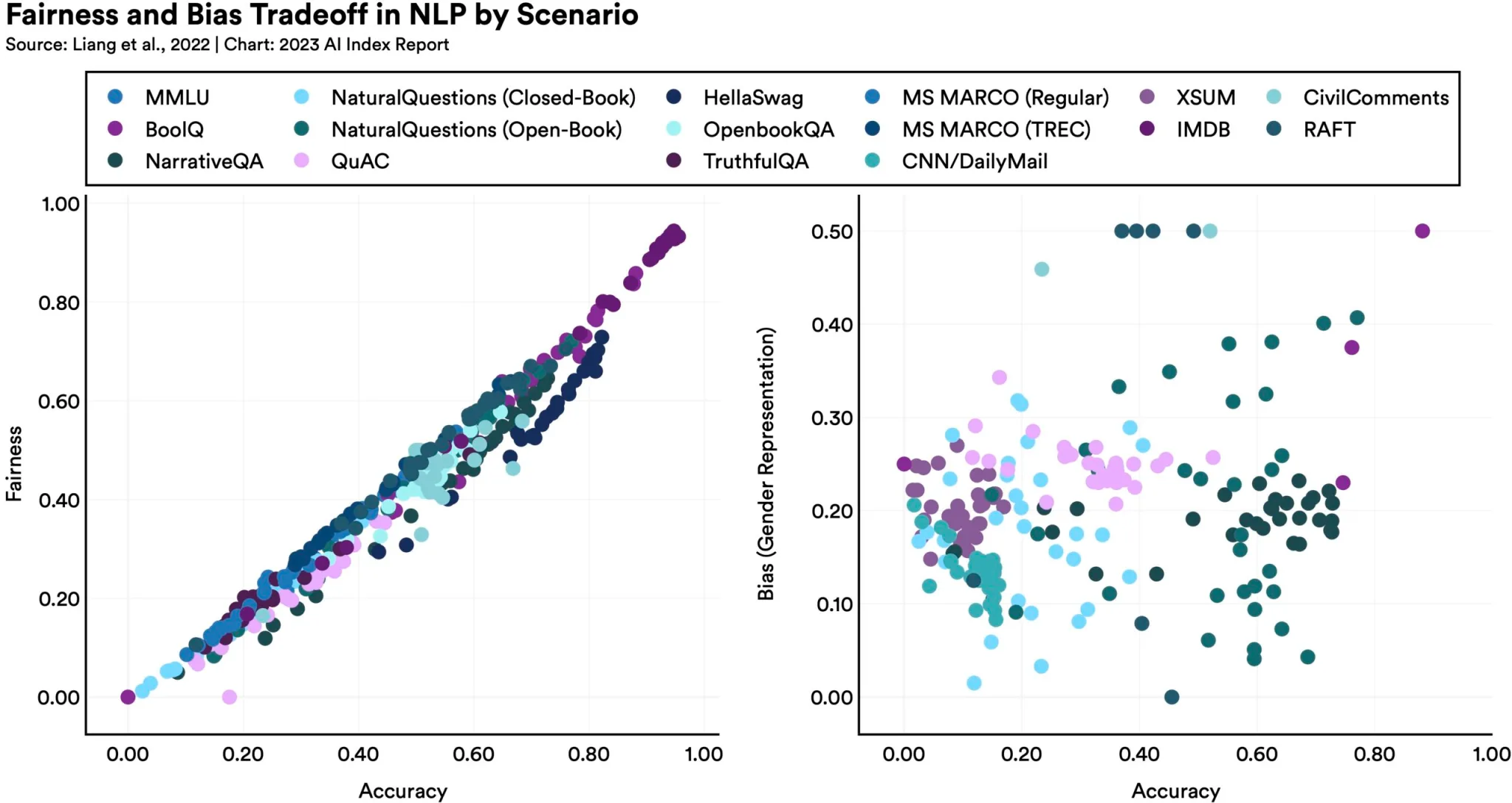
正如报告所指出的,“在某些公平性基准上表现更好的语言模型往往具有更严重的性别偏见。”为什么呢?这很难说,但它表明优化并非像大家所希望的那样简单。提高这些大型模型的性能没有简单的解决方案,部分原因是我们并未真正理解它们是如何工作的。
事实核实是一个听起来非常适合人工智能的领域:在索引了大量网络信息之后,它可以评估陈述并返回它们是否得到真实来源支持的置信度等。然而,事实远非如此。人工智能实际上在评估事实性方面表现得特别糟糕,风险并非它们作为不可靠的检查者,而是它们本身成为有力的误导性信息来源。已经创建了许多研究和数据集来测试和改进AI的事实核实能力,但到目前为止,我们的进展仍然基本处于起点。
幸运的是,在这方面的兴趣大幅上升,原因很明显,如果人们觉得无法信任人工智能,整个行业将受到影响。在ACM公平性、问责性和透明度会议以及NeurIPS上,公平性、隐私和可解释性等问题得到了更多关注和讨论。
这些突出内容仍然留下了很多细节。然而,HAI团队在组织内容方面做得非常好,阅读了这里的高层次内容后,您可以下载完整的论文,并深入了解任何引起您兴趣的主题。
斯坦福报告原文:
此处内容需要权限查看


